[러닝 파이썬(제5판)]_오탈자
현재까지 발견된 위 책의 오탈자 정보와 오류, 그리고 보다 매끄러운 문장을 위해 수정한 내용을 안내해드립니다. 번역과 편집 시에 미처 확인하지 못하고 불편을 끼쳐드려 죄송하다는 말씀을 드립니다. 아래의 오탈자 사항은 추후 재쇄 시에 반영하도록 하겠습니다.
이외의 오탈자 정보를 발견하시면 옮긴이(ulzima@gmail.com)나 출판사(readers.jpub@gmail.com)로 연락주시면 고맙겠습니다.
최종수정일자: 2020년 12월 1일
2쇄본 오탈자
(업데이트순)
상편 402쪽 위에서 세 번째 줄 (jj 님 제보)
또한 문은 어디선가 불쑥 나타날 수 있으며 => 또한 문은 객체가 등장하는 곳이며
상편 412쪽 밑에서 여덟 번째 줄 (jj 님 제보)
(그 외에도 전체 프로그램을 한 라인에 밀어 넣을 수도 있지만, => (그렇지 않으면, 전체 프로그램을 한 라인에 밀어 넣을 수도 있게 될테지만,
상편 415쪽 코드 (jj 님 제보)
input('Enter text') => input('Enter text:')
if reply = => if reply ==
상편 416쪽 부연 설명 부분의 밑에서 두 번째 줄 (jj 님 제보)
마친 파이썬 코드인 것처럼 => 마치 파이썬 코드인 것처럼
상편 428쪽 위에서 다섯 번째 줄 (jj 님 제보)
모든 이진 표현식 연산자 => 모든 이항 표현식 연산자
상편 432쪽 위에서 두 번째 줄 (jj 님 제보)
문자열로 처리하는 것이 => 연결하여 처리하는 것이
상편 443쪽 두 번째 구두점 문단 부분 (jj 님 제보)
여덟 번째 줄
파이썬 2.3까지는 => 파이썬 2.3 이전까지는
하단 주석 부분
파이썬의 또 다른 구현인 표준 CPython에서는 적어도 => 적어도 표준 CPython에서는 그렇다. 파이썬의 또 다른 구현들에서는
상편 444쪽 부연 설명 부분 밑에서 여덟 번째 줄 (jj 님 제보)
오랜 시간 동안 단계적으로 도입 중이다. => 오랜 시간 동안 단계적으로 도입 중이었다.
상편 454쪽 표 11-5의 테이블 두 번째 열의 항목명 (jj 님 제보)
파이썬 3.X문 => 파이썬 3.X 함수
상편 475쪽 밑에서 여섯 번째 줄 (jj 님 제보)
이러한 이유로 인해 블록 안에서 => 이러한 이유로 인해 하나의 블록 안에서
상편 476쪽 밑에서 네 번째 줄 (jj 님 제보)
밀어 넣이기 위해 => 밀어 넣기 위해
상편 478쪽 위에서 여덟 번째 줄 (jj 님 제보)
\naaa\nbbb\nccc이 할당되며 => \naaaa\nbbbb\ncccc이 할당되며
상편 496쪽 밑에서 두 번째 줄 (jj 님 제보)
또는 가변 객체 안의 => 또는 반복 가능 객체 안의
상편 497쪽 위에서 첫 번째 줄, 위에서 여섯 번째 줄 (jj 님 제보)
가변 객체 => 반복 가능 객체
상편 502쪽 위에서 첫 번째 줄 (jj 님 제보)
데이터의 열로부터 => 데이터의 행으로부터
상편 505쪽 부연 설명 부분 (jj 님 제보)
밑에서 14번째 줄
임의의 가변 객체는 허용되지 않는다. => 임의의 반복 가능 객체는 허용되지 않는다.
밑에서 첫 번째 줄
가변 객체 => 반복 객체
상편 506쪽 밑에서 12번째 줄 (jj 님 제보)
내장 enumerate 함수는 가변 객체의 => 내장 enumerate 함수는 반복 가능 객체의
상편 507쪽 밑에서 아홉 번째 줄 (jj 님 제보)
이와 같은 가변 객체에 => 이와 같은 반복 객체에
상편 513쪽 (jj 님 제보)
위에서 아홉 번째 줄
출력하기 위해 zip으로 감싸야만 하는 => 출력하기 위해 list로 감싸야만 하는
위에서 열 번째 줄
다시 이야기하지만, 가변 객체에 => 다시 이야기하지만, 반복 가능한 객체에
상편 514쪽 위에서 다섯 번째 줄 (jj 님 제보)
(실제로, 파일을 포함한 모든 가변 객체), => (실제로, 파일을 포함한 모든 반복 가능한 객체),
상편 520쪽 세 번째 코드의 위에서 두 번째 줄 (jj 님 제보)
learing-python => learning-python
상편 521쪽 위에서 네 번째 줄, 위에서 여덟 번째 줄, 밑에서 여섯 번째 줄 (jj 님 제보)
가변 객체 => 반복 가능 객체
상편 524쪽 코드 위에서 첫 번째 줄 (jj 님 제보)
end' ' => end=' '
상편 525쪽 부연 설명 부분의 위에서 다섯 번째 줄 (jj 님 제보)
이 두 호출은 앞서 이미 정의한 바 있다. => 이 두 호출은 앞으로 정의할 것이다.
상편 525쪽 밑에서 두 번째 줄 (jj 님 제보)
다음 라인으로 진행한다. => 이 메서드는 호출할 때마다 다음 라인으로 진행한다.
상편 537쪽 위에서 다섯 번째 줄 (jj 님 제보)
시퀀스에 포함된 각 아이템에 "대한 연산의" 연산을 수행하는 => 시퀀스에 포함된 각 아이템에 대해 연산을 수행하는
상편 540쪽 세 번째 코드의 실행 결과 (jj 님 제보)
['al', ... 'cl', 'cm', 'cl'] => ['al', ... 'cl', 'cm', 'cn']
상편 545쪽 위에서 다섯 번째 줄, 위에서 일곱 번째 줄 (jj 님 제보)
집합 컴프리헨션과 딕셔너리는 => 집합 컴프리헨션과 딕셔너리 컴프리헨션은
상편 550쪽 밑에서 여덟 번째 줄 (jj 님 제보)
파이썬 3.X에서 zip, 그리고 filter 내장 함수는 => 파이썬 3.X에서 map, zip, 그리고 filter 내장 함수는
상편 541쪽 부연 설명 두 번째 문단 (jj 님 제보)
첫 번째 줄
CPython 2.7과 3.6에서 일부 테스트에서 해당하는 => CPython 2.7과 3.6의 일부 테스트에서 대응하는
두 번째 줄
또 다른 테스트에서는 아주 미묘하고 빠르게 실행되기도 하며, => 또 다른 테스트에서는 아주 미묘하게 빠른 정도이기도 하며,
상편 552쪽 (jj 님 제보)
위에서 네 번째 줄
range 객체가 내장된 range 함수와 어떻게 다른지 => range 객체가 내장된 zip, map, filter와 어떻게 다른지
위에서 여섯 번째 줄
자신의 위치를 독립적으로 기억하는 range 객체의 결과를 통해 다수의 반복자를 지원한다. => range 객체의 결과에 대해 자신의 위치를 독립적으로 기억하는 다수의 반복자를 지원한다.
상편 553쪽 코드에서 밑에서 다섯 번째 줄(콤마 없음) (jj 님 제보)
I1, I2 = iter(R) iter(R) => I1, I2 = iter(R), iter(R)
상편 556쪽 위에서 아홉 번째 줄 (jj 님 제보)
가변 객체에 포함된 => 반복 객체에 포함된
상편 559쪽 위에서 다섯 번째 줄 (jj 님 제보)
셸에서 일반적인 테스트 => 셸에서 일반적인 텍스트
상편 567쪽 위에서 네 번째 줄 (jj 님 제보)
마침내 파이썬이 문서화 문자열을 좀 더 쉽게 표시하기 위한 도구를 추가함으로써 문서화 문자열 기술이 매우 유용하다는 것이 증명되었다.
=>
문서화 문자열이 매우 유용하다는 것이 증명되었기 때문에 파이썬은 마침내 문서화 문자열을 좀 더 쉽게 표시하기 위한 도구를 추가했다.
상편 595쪽 위에서 여섯 번째 줄 (jj 님 제보)
아무 딕셔너리 준비없이 => 아무 사전 준비없이
상편 597쪽 목록의 두 번째 항목 (jj 님 제보)
"파이썬에서 인수는 할당에 의해 함수에 전달된다.” (* 해당 문장의 굵게 효과 제거!)
상편 605쪽 부연 설명 부분 (jj 님 제보)
_contains_ => __contains__
_iter_ => __iter__
_getitem_ => __getitem__
상편 609쪽 밑에서 여섯 번째 줄 (jj 님 제보)
긍정적인 면을 보자면, 전역 범위가 => 긍정적인 면을 보자면, 범위가
상편 619쪽 두 번째 코드에서 두 번째 주석 (jj 님 제보)
원하는 것은 전역임 => 원하는 것은 지역임
상편 621쪽 위에서 첫 번째 줄 (jj 님 제보)
파이썬의 선언문 중, 유일하게 약간 닮은꼴이라고 => 파이썬에서 유일하게 선언문과 닮았다고
상편 626쪽 첫 번째 코드 (jj 님 제보)
glob2() => glob2():
test() => test():
상편 630쪽 위에서 세 번째 줄 (jj 님 제보)
다음과 같이 => 위와 같이
상편 633쪽 두 번째 코드 (jj 님 제보)
f1() => f1():
상편 634쪽 두 번째 코드 (jj 님 제보)
func() => func():
상편 638쪽 (jj 님 제보)
밑에서 열 번째 줄
함수 선언한 지역 범위 => 함수에서 선언한 지역 범위
밑에서 첫 번째 줄
nonlocal 문은 바깥쪽 범위의 이름을 단순히 참조하는 것. 아니라 변경이 필요할 때 사용된다. => nonlocal 문은 바깥쪽 범위의 이름을 단순히 참조하는 것뿐만 아니라 변경이 필요할 때도 사용된다.
상편 642쪽 (jj 님 제보)
코드의 두 번째 줄
nonlocal sapm => nonlocal spam
첫 번째 문단 세 번째 줄
아니면 외부 모듈에 할당되어야 할까? => 아니면 외부에 위치한 모듈에 할당되어야 할까?
상편 650쪽 (jj 님 제보)
세 번째 코드의 밑에서 네 번째 줄
builtin.open = self => builtins.open = self
세 번째 코드의 밑에서 두 번째 줄
%self.id => % self.id
상편 664쪽 표 18-1의 마지막 행 (jj 님 제보)
def func(*기타, 이름=값) => def func(*, 이름=값)
상편 666쪽 부연 설명 부분 밑에서 세 번째 줄 (jj 님 제보)
def f() → value 형식 => def f() => value 형식 (* 화살표 모양 수정)
상편 667쪽 밑에서 네 번째 줄 (jj 님 제보)
함수 인수를 선택할 수 있도록 한다. => 함수 인수를 생략할 수 있도록 한다.
상편 670쪽 위에서 여섯 번째 줄 (jj 님 제보)
키워드를 딕셔너리로 전환함으로써 key 호출 => 키워드 인수들을 딕셔너리로 전환함으로써 keys 호출
상편 675쪽 밑에서 네 번째 줄 (jj 님 제보)
지정된 인수로 작성된다. => 이름있는 인수로 작성된다.
상편 695쪽 밑에서 두 번째 줄 (jj 님 제보)
가장 직관적인 방법이다. => * 두 번 들어가 있는 해당 문장 중 하나를 삭제
상편 702쪽 밑에서 네 번째 줄 (jj 님 제보)
이미 처리된 상태를 추가하여 => 이미 처리된 상태를 추가하는 것을
상편 706쪽 위에서 두 번째 줄 (jj 님 제보)
1장에서 소개된 => 13장에서 소개된
상편 733쪽 밑에서 일곱 번째 줄 (jj 님 제보)
이러한 코드는 전 리스트 프로그래머를 => 이러한 코드는 전에 Lisp을 경험해본 프로그래머를
상편 734쪽 세 번째 코드 박스 세 번째 줄 (jj 님 제보)
M[i][len(M)-1-i] => [M[i][[len(M)-1-i] (* 앞에 여는 대괄호 추가)
상편 735쪽 밑에서 다섯 번째 줄 (jj 님 제보)
각 열에 대해 결과 행렬의 한 열을 => 각 행에 대해 결과 행렬의 한 행을
상편 743쪽 위에서 일곱 번째 줄 (jj 님 제보)
제너레이터는 자동으로 => 제너레이터 함수는 자동으로
상편 745쪽 (jj 님 제보)
위에서 다섯 번째 줄
수동으로 저장하기 위한 => 수동으로 저장하는 것에 대한
위에서 11번째 줄
튜플 호출 => tuple 호출
상편 746쪽 위에서 첫 번째 줄 (jj 님 제보)
모든 결과를 한 번에 생성하므로 결과 세트가 너무 큰 경우에는 그중 일부 요소를 => 결과 세트가 너무 커서 한 번에 생성할 수 없는 경우에는 그 중 일부 요소만을
상편 748쪽 위에서 네 번째 줄 (jj 님 제보)
또한, 반복 객체는 실행 중인 동안 제너레이터의 코드 위치와 위 표현식에서 변수 x가 이 역할을 한다. => 또한, 반복 객체는 실행 중인 동안 제너레이터의 상태(제너레이터의 코드 위치와 위 표현식에서 변수 x)를 유지한다.
상편 750쪽 밑에서 네 번째 줄 (jj 님 제보)
테스트 => 텍스트
상편 751쪽 첫 번째 코드의 다섯 번째 줄 (jj 님 제보)
''.join(x,upper() => ''.join(x.upper()
상편 752쪽 두 번째 코드의 다섯 번째 줄 (jj 님 제보)
(-1, 0 1) => (-1, 0, 1)
상편 756쪽의 중간에 있는 코드 (jj 님 제보)
for c i 'SPAM' => for c in 'SPAM'
상편 758쪽 부연 설명의 제목 (jj 님 제보)
확장으로부터의 파이썬 3.3 yield => 파이썬 3.3의 yield from 확장
상편 760쪽 위에서 첫 번째 줄 (jj 님 제보)
특정 유형의 => 특정 타입의
상편 775쪽 첫 번째 코드 (jj 님 제보)
def mymap(func, *seqs); => def mymap(func, *seqs):
res = [] => (* 삭제)
for args in zip(seqs)) => for args in zip(*seqs)
def mymap(func, "seqs); => def mymap(func, *seqs)
상편 776쪽 위에서 두 번째 줄, 위에서 세 번째 줄 (jj 님 제보)
가변 객체 => 반복 객체
상편 778쪽 코드의 다섯 번째 줄 (jj 님 제보)
for in range(minlen) => for i in range(minlen)
상편 779쪽 세 번째 코드 (jj 님 제보)
def myzip("args): => def myzip(*args):
상편 781쪽 위에서 두 번째 줄 (jj 님 제보)
이러한 확장들 내에서 => 이러한 표현식들 내에서
상편 783쪽 마지말 코드 박스 (jj 님 제보)
{0: 0, 2: 4, 4: 16, 6: 36, 8: 64} (* 실행 결과 누락됨. 여섯 번째 줄로 해당 코드 추가)
상편 784쪽 첫 번째 코드의 세 번째 줄 (jj 님 제보)
">>> {x * y" => ">>> {x + y"
상편 794쪽 (jj 님 제보)
위에서 두 번째 줄
다섯 가지 테스트 함수 각각을 순서대로 천만번 실행한 결과에 대한 => 다섯 가지 테스트 함수 각각이 순서대로 천만개의 산출을 실행한
위에서 네 번째 줄
총 2500만번의 산출이 발생한다 => 총 2억 5천만번의 산출이 발생한다
상편 823쪽 밑에서 세 번째 줄 (jj 님 제보)
최신 버전 파이썬에서는 이와 같은 경우, 좀 더 구체적으로는 앞 예제에서 보여 준 ‘unbound local’ 에러 메시지에 대한 이슈로 인해 이 부분에 대한 개선이 있었다
=>
최신 버전 파이썬은 이런 실수를 피하고자 앞 예제에서 보이는 것처럼 보다 구체적인 "unbound local" 에러 메시지를 보여주도록 개선했다
상편 840쪽 위에서 여섯 번째 줄 (jj 님 제보)
모듈 파일도 코드 파일이긴 하지만 직접 => 모듈 파일도 코드 파일이긴 하지만 일반적으로 직접
상편 842쪽 위에서 일곱 번째 줄 (jj 님 제보)
임포트의 표기법은 => 임포트의 개념은
상편 844쪽 밑에서 아홉 번째 줄 (jj 님 제보)
파일 수정 횟수와 => 파일 수정 시간과
상편 849쪽 밑에서 두 번째 줄 (jj 님 제보)
site-package 홈 => site-packages 홈
상편 851쪽 밑에서 12번째 줄 (jj 님 제보)
서드파티 확장 기능이 설치된 곳에서는 => 보통 서드파티 확장 기능이 설치되는
상편 856쪽 부연 설명 부분의 위에서 두 번째 줄 (jj 님 제보)
파이썬 3.6의 'What's New?' => 파이썬 3.3의 'What's New?'
상편 857쪽의 부연 설명 부분의 위에서 네 번째 줄 (jj 님 제보)
setupa.py => setup.py
상편 862쪽의 밑에서 일곱 번째 줄 (jj 님 제보)
실제로, 패키지 임포트(...)에서 사용되는 모듈 파일의 이름과 디렉터리의 이름 모두
=>
실제로, 모듈 파일의 이름과 패키지 임포트(...)에서 사용되는 디렉터리의 이름 모두
상편 865쪽 밑에서 네 번째 줄 (jj 님 제보)
파일 또는 프로세스당 => 프로세스당 각 파일을
상편 873쪽 (jj 님 제보)
밑에서 일곱 번째 줄
모듈 객체를 생성한다. => 모듈 속성을 생성한다.
밑에서 두 번째 줄
객체를 조회하는 것이지만, => 뷰 객체(view object)를 조회하는 것이지만,
상편 875쪽 코드의 마지막 주석 (jj 님 제보)
다른 모듈에서 이름을 볼 수 없음 => 다른 모듈에 있는 이름을 볼 수 없음
상편 877쪽 밑에서 세 번째 줄 (jj 님 제보)
mod1과 mod2 내부에서 => mod1에서 mod2는
상편 879쪽 코드 박스에서 (jj 님 제보)
* d 행 삭제(주석은 그대로 유지)
상편 882쪽 위에서 다섯 번째 줄 (jj 님 제보)
리로드 연산은 이름들을 매우 이상한 => from에 대한 리로드 연산은 이름들을 매우 이상한
상편 886쪽 밑에서 아홉 번째 줄
디렉리가있으며, => 디렉터리가 있으며,
상편 905쪽 위에서 여섯 번째 줄 (jj 님 제보)
절대 임포트문 모든 디렉터리를 sys.path의 패키지 루트 항목 아래로
=>
절대 임포트문은 sys.path의 패키지 루트 항목 아래에 있는 모든 디렉터리를
상편 905쪽 첫 번째 코드의 주석 (jj 님 제보)
시스템 컨테이너는 sys.path상에만 => system을 포함하는 디렉터리만 sys.path에
상편 921쪽 밑에서 일곱 번째 줄 (jj 님 제보)
결쳐 나눠지고, => 걸쳐 나눠지고,
상편 923쪽 (jj 님 제보)
위에서 두 번째 줄
반복 객체로 시작하는 => 반복 객체로 설정되는
위에서 열 번째 줄
디렉터리들과 일종의 가상 연결이 이루어진다. => 디렉터리들에 대한 일종의 가상 연결(concatenation)이 된다.
상편 944쪽 위에서 여덟 번째 줄 (jj 님 제보)
입력값을 위한 셸 유저를 띄우기 위해 => 입력값을 셸 사용자로부터 입력받기 위해
상편 945쪽 위에서 첫 번째 줄 (jj 님 제보)
텍스트 문자열에서의 순서(정수)를 가리키는 유니코드 코드
=>
텍스트 문자열에서의 문자를 가리키는 유니코드 코드 포인트 서수(정수)
상편 171쪽 위에서 네 번째 줄 (jj 님 제보)
"부호부와 지수부," => (* 해당 부분 삭제)
상편 172쪽 밑에서 여덟 번째 줄 (jj 님 제보)
복소수는 complex(real, imag)가 내장된 호출을 사용하여 만들 수 있다.
=>
복소수는 내장된 호출 complex(real, imag)을 사용하여 만들 수도 있다.
상편 174쪽의 표 5-2 (jj 님 제보)
(*표 셀 구성을 다음으로 교체)
|
연산자 |
설명 |
|
yield x |
send 프로토콜 제너레이터 함수 |
|
lambda args: expression |
익명 함수 생성 |
|
x if y else z |
삼중 선택(y가 true인 경우에만 x가 실행된다) |
|
x or y |
논리 OR(y는 x가 false인 경우에만 실행된다) |
|
x and y |
논리 AND(y는 x가 true인 경우에만 실행된다) |
|
not x |
논리 부정 |
|
x in y, x not in y x is y, x is not y x < y,x <= y,x > y,x >= y x == y,x != y |
멤버십(반복 객체, 집합) 객체 동일성 테스트 크기 비교, 부분 집합과 상위집합 값 등가 비교 연산자 |
|
x | y |
비트 연산자 OR, 합집합 |
|
x ^ y |
비트 연산자 XOR, 대칭 차집합 |
|
x & y |
비트 연산자 AND, 교집합 |
|
x << y, x >> y |
X를 왼쪽 또는 오른쪽으로 y 비트만큼 이동 |
|
x + y x – y |
더하기, 연결 빼기, 차집합 |
|
x * y x % y x / y, x // y |
곱하기, 반복 나머지, 포맷 나누기: true 나누기와 floor 나누기 |
|
-x, +x ~x |
부정, 식별 비트 연산자 NOT(부정) |
|
x ** y |
거듭제곱(지수) |
|
x[i] x[i:j:k] x(...) x.attr |
인덱싱(시퀀스, 매핑) 슬라이싱 호출(함수, 메서드, 클래스, 기타 콜러블(callable)) 속성 참조 |
|
(...) [...] {...} |
튜플, 표현식, 제너레이터 표현식 리스트, 리스트 컴프리헨션 딕셔너리, 집합, 집합 컴프리헨션과 딕셔너리 컴프리헨션 |
상편 175쪽 위에서 여섯 번째 줄 (jj 님 제보)
역인용 부호 표현식 'x'는 => 역인용 부호 표현식 `x`는
상편 183쪽 str과 repr 출력 형식의 밑에서 세 번째 줄 (jj 님 제보)
디코드하기 위한 인코딩 이름으로 사용된다. => 디코드하기 위해 인코딩 이름을 넘기면서 호출되기도 한다.
상편 184쪽 위에서 일곱 번째 줄 (jj 님 제보)
다음 부울 테스트 => 부울 테스트
상편 187쪽 위에서 세 번째 줄 (jj 님 제보)
이러한 점은 / 연산자가 파이썬 2.X에서 타입 의존적인 동작을 하는 것과 유사해 보일 수도 있지만, / 연산자 자체의 타입 의존성은 3.X에서 결과 타입이 부동 소수점 수 타입으로 고정되는 계기가 되었으며, 3.X에서 / 연산자의 반환 타입은 반환 타입이 차이가 날 때보다 훨씬 덜 중요해졌다.
=>
이러한 점은 3.X에서 그 동작이 바뀐 계기가 된 2.X에서의 / 연산자의 타입 의존적인 동작과 유사해보일 수도 있지만, 리턴 값의 타입만 의존할 뿐 리턴 값 자체가 의존하진 않으므로 덜 치명적이다(예를 들어 2.X에서 3/2=1, 3/2.0=1.5이라서 값 자체가 달라지지만, 3.X에서는 3//2=1, 3//2.0=1.0).
상편 192쪽 세 번째 문단 첫 번째 줄 (jj 님 제보)
복소수는 자신의 각 부분을 속성처럼 => 복소수는 속성을 통해 자신의 각 부분을
상편 196쪽 두 번째 코드의 마지막 주석 (jj 님 제보)
1진수 => 16진수
상편 202쪽 마지막 코드의 마지막 줄 (jj 님 제보)
>>> pay Decimal('2000.33')
=>
>>> pay
Decimal('2000.33')
상편 204쪽 밑에서 두 번째 줄 (jj 님 제보)
분수와 소수의 수치 정밀도는 수치 정밀도는 부동 소수점 수 타입 계산과는 다르며, 내부의 부동 소수점 수 하드웨어의 한계에 제약을 받는다는 점에 주의하자.
=>
분수와 소수의 수치 정밀도는 내부의 부동 소수점 수 하드웨어의 한계에 제약을 받는 부동 소수점 수 타입 계산과는 다르다는 점에 주의하자.
상편 212쪽 첫 번째 코드의 두 번째 주석 (jj 님 제보)
가변 객체 안의 모든 아이템 추가 => 반복 가능 객체 안의 모든 아이템 추가
상편 214쪽 밑에서 아홉 번째 줄 (jj 님 제보)
리스트 컴프리헨션은 루프를 반복할 때마다 => 집합 컴프리헨션은 루프를 반복할 때마다
상편 239쪽 위에서 세 번째 줄 (jj 님 제보)
정렬되지 않은 => 정렬된
상편 245쪽 밑에서 두 번째 줄 (jj 님 제보)
시퀀스처럼 보여 주지만, => 이스케이프 시퀀스로 보여 주지만,
상편 249쪽 위에서 첫 번째 줄 (jj 님 제보)
그러나 이 방법이 표 7-2에 나열된 모든 시퀀스에 대해 동일하게 동작하지 않는다면, 여러분은 아마도 이 동작에 의존할 수 없을 것이다.
=>
그러나 표 7-2에 나열된 모든 유효한 이스케이프 시퀀스를 외우고 있는 게 아닌 한, 여러분은 아마도 이 동작에 의존하고 싶진 않을 것이다.
상편 250쪽 부연 설명 부분 밑에서 네 번째 줄 (jj 님 제보)
두 번째 역슬래시를 잘라내거나(r'1\nb\tc\ \'[:-1]), => 두 번째 역슬래시를 잘라내거나(r'1\nb\tc\\'[:-1]),
상편 250쪽 부연 설명 부분 밑에서 세 번째 줄 (jj 님 제보)
슬래시만 이중으로 => 역슬래시만 이중으로
상편 262쪽 위에서 네 번째 줄 (jj 님 제보)
실제 바이너리 값을 반환한다 => 실제 숫자 값을 반환한다
상편 262쪽 (jj 님 제보)
위에서 여섯 번째 줄
대응하는 유니코드 또는 ‘코드 포인트’ 사이를 서로 변환하며, => 대응하는 유니코드 서수 값 또는 '코드 포인트' 사이를 서로 변환하며,
위에서 일곱 번째 줄
유니코드와 코드 포인트는 => 유니코드 서수 값 또는 코드 포인트는
상편 271쪽 위에서 세 번째 줄 (jj 님 제보)
또한 어떤 구분자의 종류로 데이터를 분리하는 대신, => 대신 어떤 구분자의 종류가 데이터를 분리한다면,
상편 275쪽 밑에서 14번째 줄 (jj 님 제보)
문자열 포매팅 메서드 호출: '...{}...'.format (값들) => 문자열 포매팅 메서드 호출: '...{}...'.format(값들)
상편 276쪽 밑에서 네 번째 줄 (jj 님 제보)
(또는 튜플에 내장 객체들) => (또는 튜플에 내장된 객체들)
상편 279쪽 위에서 첫 번째 줄 (jj 님 제보)
숫자 기호(+) => 숫자 부호(+)
상편 293쪽 밑에서 열 번째 줄 (jj 님 제보)
여기서 comma 함수는 => 여기서 commas 함수는
상편 306쪽 표 8-1 (jj 님 제보)
밑에서 두 번째 행(우측 열)
리스트 컴프리헨션과 맵(4장, 14장, 20장) => 리스트 컴프리헨션(4장, 14장, 20장)
맨 아래 행(우측 열)
맵 => 맵(4장, 14장, 20장)
상편 306쪽 첫 번째 문단 (jj 님 제보)
두 번째 열 => 두 번째 행
(3열) => (3행)
(1열) => (1행)
상편 311쪽 페이지 하단의 부연 설명 부분 두 번째 줄 (jj 님 제보)
왼쪽에서 삭제가 발생하기 먼저 가져오기 때문에 => 왼쪽에서 삭제가 발생하기 전에 먼저 가져오기 때문에
상편 313쪽 페이지 하단의 부연 설명 부분 네 번째 줄 (jj 님 제보)
예를 들어, L.insert(0, X) 구문 마찬가지로 => 예를 들어, L.insert(0, X) 구문도 마찬가지로
상편 314쪽 첫 번째 줄 (jj 님 제보)
* 문장 맨 앞에 ‘key 인수는’을 추가
상편 318쪽 밑에서 두 번째 줄 (jj 님 제보)
해당 값은 다수의 키를 저장할 수 있다. => 주어진 값 자체는 다수의 키에 연관되어 저장될 수 있다.
상편 321쪽 밑에서 여덟 번째 줄 (jj 님 제보)
가운데 문단 맨 끝에 ‘(파이썬 3.6부터 딕셔너리는 삽입 순서대로 정렬된다).’를 추가
상편 329쪽 세 번째 코드의 주석 (jj 님 제보)
# ;문들을 구분: 10장 참고 => # ;는 문들을 구분: 10장 참고
상편 330쪽 밑에서 여섯 번째 줄 (jj 님 제보)
예를 들면 키가 존재하지 않는 경우에는 기본값을 제공하기 위해 if문을 사용하거나, 명시적인 예외를 붙잡아 처리하는 try문을 사용하거나, 또는 단순히 딕셔너리의 get 메서드를 사용하여 사전에 미리 키가 존재하는지 확인할 수 있다.
=>
예를 들면 사전에 미리 키가 존재하는지 확인하기 위해 if문을 사용하거나, 예외를 명시적으로 붙잡아 처리하는 try문을 사용하거나, 또는 단순히 딕셔너리의 get 메서드를 사용하여 키가 존재하지 않는 경우에는 기본값을 제공할 수 있다.
상편 330쪽 코드의 세 번째 주석 (jj 님 제보)
# 인덱스 try => # 인덱스를 시도
상편 331쪽 두 번째 코드 (jj 님 제보)
'web': 'www.bobs.org/~Bob' (* 물결 표시가 문자 B와 이상하게 겹쳐 있음)
상편 336쪽 밑에서 일곱 번째 줄 (jj 님 제보)
항상 이 둘을 함께 묶어서 딕셔너리를 리스트처럼 만들 수 있다. => 항상 이 둘 각각을 리스트로 만든 뒤 묶어서 딕셔너리로 만들 수 있다.
상편 337쪽 첫 번째 코드의 주석, 두 번째 코드의 주석 (jj 님 제보)
가변 객체 => 반복 가능 객체
상편 338쪽 밑에서 네 번째 줄 (jj 님 제보)
14장에서 가변 객체의 => 14장에서 반복 가능한 객체의
상편 339쪽 위에서 첫 번째 줄 (jj 님 제보)
파이썬에서 루프 구조는 반복 때마다 하나의 결과를 생성하기 위해 강제로 가변 객체로 만들므로 대화형 프롬프트에서...
=>
파이썬에서 루프 구조는 반복 가능한 객체로 하여금 각 반복 때마다 자동으로 하나씩 결과를 생성하도록 하므로 대화형 프롬프트에서...
상편 339쪽 위에서 네 번째 줄 (jj 님 제보)
또한, 3.X에서 딕셔너리는 여전히 연속적인 키를 반환하는 그 자체가 반복자(iterator)다.
=>
또한, 3.X에서도 여전히 딕셔너리는 스스로, 연속적인 키를 반환하는 반복자(iterator)를 갖는다.
상편 340쪽 밑에서 네 번째 줄 (jj 님 제보)
딕셔너리의 항목들은 반드시 => 딕셔너리의 값의 뷰의 항목들은 반드시
상편 342쪽 첫 번째 코드의 네 번째 주석 (jj 님 제보)
sorted()는 모든 가변 객체를 허용함 => sorted()는 모든 반복 가능한 객체를 허용함
상편 354쪽 위에서 일곱 번째 줄, 세 번째 코드의 두 번째 주석 (jj 님 제보)
튜플 항목들로 변환된 리스트 => 튜플의 리스트로 변환된 항목들
상편 359쪽 마지막 줄 (jj 님 제보)
* ‘스크립트를’을 삭제
상편 360쪽 위에서 열 번째 줄 (jj 님 제보)
엄밀히 말하면, 컬렉션 시에 => 엄밀히 말하면, 가비지 컬렉션 시에
상편 362쪽 밑에서 일곱 번째 줄 (jj 님 제보)
파일 끝 문자 변환을 기본으로 수행한다. => 라인 끝 문자 변환을 기본으로 수행한다.
상편 368쪽 밑에서 일곱 번째 줄 (jj 님 제보)
게다가 JSON은 구문적으로 파이썬 사진과 => 게다가 JSON은 구문적으로 파이썬 딕셔너리와
상편 371쪽 첫 번째 코드의 3행 (jj 님 제보)
* >>> data b'에서 b'를 다음 행의 가장 앞으로 이동
상편 373쪽 위에서 세 번째 줄 (jj 님 제보)
pickle을 이용할 수 있는 파이썬 객체를 => pickle로 직렬화한 파이썬 객체를
상편 374쪽 위에서 열 번째 줄 (jj 님 제보)
표 9-3의 ‘문자’는 => 표 9-3의 ‘문자열’은
상편 381쪽 밑에서 13번째 줄 (jj 님 제보)
딕셔너리적으로 => 사전 편찬 순서대로(lexicographically)
상편 392쪽 (jj 님 제보)
밑에서 다섯 번째 줄
가변 객체는 직접 변경할 수 없다. => 불변 객체는 직접 변경할 수 없다.
밑에서 두 번째 줄
튜플과 문자열 같은 가변 객체를 => 튜플과 문자열 같은 불변 객체를
상편 394쪽 위에서 여덟 번째 줄 (jj 님 제보)
튜플은 가변이기 때문에 => 튜플은 불변이기 때문에
상편 45쪽 위에서 여섯 번째 줄 (jj 님 제보)
열네 번째 줄
상편 49쪽 밑에서 열한 번째 줄 (jj 님 제보)
상편 388쪽 그림 9-3 하단 흰색 배경 글상자 (JeongHwi Ra 님 제보)
가터 => 기타
상편 739쪽 맨 아래쪽 코드문 마지막 줄
[35, 40} => [35, 40]
상편 777쪽 하단 코드문 다섯 번째 줄
for in => for i in
상편 790쪽 코드문 위에서 네 번째 줄
ret = fun(*pargs, **kargs) => ret = func(*pargs, **kargs)
상편 791쪽 밑에서 네 번째 줄
>>> timer.bestof(50, timer.total 1000 str.upper, 'spam') => >>> timer.bestof(50, timer.total, 1000, str.upper, 'spam')
상편 829쪽 밑에서 일곱 번째 줄 중간부
pystoen => pystone
상편 전체적으로
고전 클래스 => 레거시 클래스
메서드 => 메소드
상편 921쪽 열한 번째 줄
'고전적' 클래스 => '레거시' 클래스
>>> res = [x + y for x in [0, 1, 2] for y in in [100, 200, 300]]
=>
>>> res = [x + y for x in [0, 1, 2] for y in [100, 200, 300]]
최종수정일자: 2018년 11월 29일
1쇄본 오탈자
(업데이트순)
상/하편 모두에서
고전 클래스 => 레거시 클래스
메서드 => 메소드
하편 1101쪽 첫 번째 예제 코드 박스 일곱 번째 줄 (현재웅 님 제보)
I.method1() I.method2()
=>
I.method1()
I.method2()
(* 한 줄로 된 내용을 두 행으로 나누어야 합니다.)
상/하편 모두에서
다시 한 번 => 다시 한번
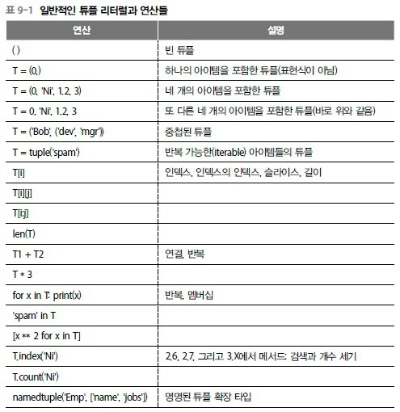
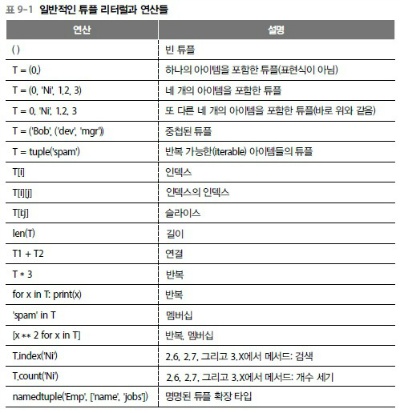
상편 349쪽 표 9-1 (Jae* Hyun 님 제보)
▼
상편 571~590쪽 사이의 파이썬 버전 표기에 관하여 (Jae* Hyun 님 제보)
버전 3.6이라 표시된 부분을 모두 3.3으로 변경
(* 이 장은 지은이가 3.2 버전과 3.3 버전을 비교하는 내용이므로 최신 3.6이 아닌 3.3 버전으로 표기되었어야 함)
상편 920쪽 하단의 옮긴이 주 (Jae* Hyun 님 제보)
현재 파이썬의 최신 버전은 3.7이고, 이 책이 집필될 당시에는 3.3이 최신 버전이다.
=>
이 책이 집필될 당시의 최신 파이썬 버전은 3.3이었으나, 옮긴이는 번역 시점의 최신 버전인 3.6에서 모든 코드를 테스트했다. 부득이하게 버전 표기를 유지해야 할 곳은 3.3으로 되어 있지만, 내용을 이해하거나 테스트하는 데는 문제가 없을 것이다.
--------------------------------------10/12일자--------------------------------------
상편 8쪽 맨 마지막 줄 (Jae* Hyun 님 제보)
그러므로 일부 프로그램은 파이썬에서 C처럼 완전히 컴파일되는 언어보다 파이썬에서 더욱 느리게 실행될 것이다.
=>
그러므로 일부 프로그램은 C처럼 완전히 컴파일되는 언어보다 파이썬에서 더욱 느리게 실행될 것이다.
상편 123쪽 밑에서 두 번째 문단 (Jae* Hyun 님 제보)
파이썬의 오래된 버전에서는 부동 소수점 repr은 때로 여러분이 예상하는 것보다 더 많은 정밀도로 표시된다.
=>
파이썬의 오래된 버전에서는 부동 소수점 repr은 때로 여러분이 예상하는 것보다 더 높은 정밀도로 표시된다.
상편 181쪽 중간 예제 소스 (Jae* Hyun 님 제보)
#(4 / (2.0 +3))과 같음 [2.7 이전에서는 print를 사용] => #(4 / (2.0 + 3))과 같음
(* [ ]안 내용은 저자가 주석으로 설명을 단 것인데 조금 맥락에 안맞게 보일 수 있는 것 같아 삭제합니다.)
상편 233쪽 세 번째 줄 (Jae* Hyun 님 제보)
또한, 이러한 슬라이싱 기술은 딕셔너리가나 => 또한, 이러한 슬라이싱 기술은 딕셔너리나
상편 237쪽 학습 테스트 두 번째 소스 (Jae* Hyun 님 제보)
B= A => B = A
상편 240쪽 마지막 줄 (Jae* Hyun 님 제보)
이러한 구별 외에는 대부분 단순한 문자열 처리. => 이러한 구별 외에는 대부분 단순한 문자열 처리다.
상편 257쪽 중간 (Jae* Hyun 님 제보)
아홉 번째 줄
s[1:3]는 오프셋 1에서부터 오프셋 3까지의 아이템을 가져오며, 오프셋 3에 위치한 아이템은 제외된다.
=>
s[1:3]은 오프셋 1에서부터 오프셋 2까지의 아이템을 가져오며, 오프셋 3에 위치한 아이템은 제외된다.
11번째 줄
s[:3]는 오프셋 0에서부터 오프셋 3까지의 아이템을 가져오며, 오프셋 3에 위치한 아이템은 제외된다.
=>
s[:3]은 오프셋 0에서부터 오프셋 2까지의 아이템을 가져오며, 오프셋 3에 위치한 아이템은 제외된다.
상편 277쪽 밑에서 두 번째 문단 (Jae* Hyun 님 제보)
다시 한 번 말하지만, 포매팅은 왼쪽에 있는 문자열을 변경하지 않고 항상 새로문 문자열을 만든다는 것을 기억하자.
=>
다시 한번 말하지만, 포매팅은 왼쪽에 있는 문자열을 변경하지 않고 항상 새로운 문자열을 만든다는 것을 기억하자.
상편 296쪽 위에서 세 번째 문단 (Jae* Hyun 님 제보)
튜플 자체를 값으로 전달하여 출력해야 하는 경우 중첩된 튜플을 전달해야 한다. 또한, 드물긴 하나 튜플 자체를 값으로 전달하여 출력해야 할 경우에는 중첩된 튜플을 전달해야만 한다.
=>
결과적으로 단일 아이템은 그 자체로나 튜플로 감싼 후 제공될 수 있으며, 튜플 자체를 값으로 전달하여 출력해야 하는 경우 중첩된 튜플을 전달해야 한다.
(* 빨간색으로 표시된 문장을 삭제)
상편 308쪽 첫 번째 예제 소스 (Jae* Hyun 님 제보)
>>> res => >>> res
상편 309쪽 마지막줄 (Jae* Hyun 님 제보)
앞의 대화형 예제에서 리스트는 한 쌍의 괄호에 포함되어 있기 때문에
=>
앞의 대화형 예제에서 리스트는 한 쌍의 대괄호에 포함되어 있기 때문에
상편 전체에서 (Jae* Hyun 님 제보)
메소드 => 메서드
상편 462쪽 첫 번째 예제 소스 두 번째 줄 (Jae* Hyun 님 제보)
>> print() => >>> print()
상편 462쪽 (Jae* Hyun 님 제보)
첫 번째 문단
이와 같은 결과가 라인을 강제로 => 이와 같은 결과는 라인을 강제로
세 번째 문단 첫 번째 줄
여기서 단지 튜플에서 => 여기서 따옴표는 단순히 튜플에서
상편 483쪽 첫 번째 문단 (Jae* Hyun 님 제보)
그러나 예를 들어 다음 코드는 파이썬이 단축을 적용하지 않기 때문에 정확히 동일하지는 않다. => 그러나 예를 들어 다음 코드는 파이썬이 단축 연산(short-circuit)을 적용하지 않기 때문에 정확히 동일하지는 않다.
상편 504쪽 참고 내용 마지막 문단 (Jae* Hyun 님 제보)
또한 여기서 for 루프는 각 문자를 처리하지만, for 루프는 파일을 (한 번에 읽기에 충분한 경우) 한 번에 모두 메모리로 읽는다.
=>
또한 여기서 for 루프는 각 문자를 처리하지만, file.read()는 파일을 (한 번에 읽기에 충분한 경우) 한 번에 모두 메모리로 읽는다.
상편 506쪽 세 번째 불릿 기호 내용 (Jae* Hyun 님 제보)
(파이썬2.3 이후로 사용할 수 있는) 내장 enumerate 함수는 가변 객체의 아이템들에 대한 값과 인덱스를 생성하므로 수동으로 카운팅할 필요가 있다.
(파이썬2.3 이후로 사용할 수 있는) 내장 enumerate 함수는 가변 객체의 아이템들에 대한 값과 인덱스를 생성하므로 수동으로 카운팅할 필요가 없다.
상편 509 마지막 예제 소스 세 번째 줄 (Jae* Hyun 님 제보)
#제일 앞 아이템으로 끝으로 이동
#제일 앞 아이템을 끝으로 이동
상편 548쪽 세 번째 문단 (Jae* Hyun 님 제보)
좀 더 자세한 내용은 20장에서 살펴보겠지만, map이나 zip 같이 한 번의 탐색만을 지원하며, 새롭게 반복 객체가 된 도구들에 대해 여러 번의 반복을 지원하기 위해서 리스트로 변환할 경우에는 주의가 필요하다.
=>
좀 더 자세한 내용은 20장에서 살펴보겠지만, map과 zip 같이 한 번의 탐색만을 지원하는 새로운 반복 객체에 대한 다중 반복은 좀 더 세밀한 지원이 필요하다.
상편 571쪽 (Jae* Hyun 님 제보)
첫 번째 문단의 마지막 줄
그리고 이를 실행하는 방법은 파이썬 3.6 이후부터 변경되었다.
=>
그리고 이를 실행하는 방법은 파이썬 3.3 버전부터 변경되었다.
두 번째 불릿 기호 내용
3.6 이후부터 이전 GUI 클라이언트는 => 파이썬 3.3 버전부터 이전 GUI 클라이언트는
상편 602쪽 주석 내용 (Jae* Hyun 님 제보)
기본 개념은 '당신의 코드는 객체가 꽥꽥 울지 않는 한, 그 객체가 오리인지 아닌지에 대해서는 상관하지 않는다'는 것이다.
=>
기본 개념은 '당신의 코드는 객체가 꽥꽥하고 우는 한, 그 객체가 오리인지 아닌지에 대해서는 상관하지 않는다'는 것이다.
상편 664쪽 표 18-1 맨 마지막 칸 (Jae* Hyun 님 제보)
def func(*, 이름 = 값) => def func(*기타, 이름 = 값)
상편 701쪽 두 번째 예제 소스 밑에서 두 번째 줄 (Jae* Hyun 님 제보)
items.extend(front) => items[:0] = front
상편 735쪽 두 번째 예제 소스에 첫 번째 주석문 (Jae* Hyun 님 제보)
# 문을 이용한 같은 기능 => # for문을 이용한 같은 기능
상편 736쪽 첫 번째 문단 (Jae* Hyun 님 제보)
이 코드는 다음의 문 기반 코드와 같다. => 이 코드는 다음의 for문 기반 코드와 같다.
상편 751 첫 번째 예제 소스 첫 줄 (Jae* Hyun 님 제보)
>>> list = 'aaa,bbb,ccc' => >>> line = 'aaa,bbb,ccc'
상편 752쪽 세 번째 문단 (Jae* Hyun 님 제보)
예를 들어, 예를 들어, 다음은 중첩보다는 비중첩이 일반적으로 더 낫다는
=>
예를 들어, 다음은 중첩보다는 비중첩이 일반적으로 더 낫다는
상편 765쪽 예제 소스 첫 번째 함수 (Jae* Hyun 님 제보)
>>> def scramble(seq):
for i in range(len(seq)):
seq = seq[1:] + seq[:1]
yield seq
=>
>>> def scramble(seq):
for i in range(len(seq)):
seq = seq[1:] + seq[:1]
yield seq
(* 들여쓰기가 틀림. 세, 네 번째 줄을 한 번 더 들여써야 합니다.)
상편 794쪽 예제 소스 밑에서 열 번째 줄 (Jae* Hyun 님 제보)
def getFunc(): => def genFunc():
상편 818쪽 첫 번째 문단 (Jae* Hyun 님 제보)
비록 사용자 정의 함수가 내장 함수보다 더 느릴 수는 있지만, 일반적으로 함수가 내장인지 아닌지가 성능에 영향을 많이 주는 것 같아 보인다.
=>
비록 사용자 정의 함수가 내장 함수보다 더 느릴 수는 있지만, 일반적으로 함수가 내장이든 아니든 함수 자체가 속도 면에서 큰 부분을 차지한다는 것을 알 수 있다.
상편 822쪽 두 번째 문단 (Jae* Hyun 님 제보)
여러분도 알다시피, 파이썬은 함수 안에서 할당된 이름을 기본적으로 지역(지역)로 분류한다.
=>
여러분도 알다시피, 파이썬은 함수 안에서 할당된 이름을 기본적으로 지역(locals)으로 분류한다.
상편 826쪽 첫 번째 예제 소스 세 번째 줄 (Jae* Hyun 님 제보)
print((saver.x) => print(saver.x)
하편 1554쪽 예제 소스 여섯 번째 줄 (Jae* Hyun 님 제보)
# 혹은 다른 호줄 가능 객체 => # 혹은 다른 호출 가능 객체
상편 xxxiv쪽, 하편 xxxiii쪽 마지막 URL (Jae* Hyun 님 제보)
Learnin-python.com/index-book-links.html
=>
Learning-python.com/index-book-links.html
상편 554쪽 첫 번째 코드 밑에서 세 번째 줄 (Jae* Hyun 님 제보)
for k in D.kesy(): print(k, end=‘ ’)
=>
for k in D.keys(): print(k, end=‘ ’)
상편 685쪽 첫째 줄 (Jae* Hyun 님 제보)
(그러려면 전체 순열이 필요하며, 네 개의 인수의 경우 총 2네 개의 순서가 생긴다)
=>
(그러려면 전체 순열이 필요하며, 네 개의 인수의 경우 총 24개의 순서가 생긴다)
상편 718쪽 두 번째 코드 첫 번째 줄 (Jae* Hyun 님 제보)
action = (labda x : (lambda y: x+y))
=>
action = (lambda x : (lambda y: x+y))
상편 733쪽 첫 번째 코드 첫 번째 줄 (Jae* Hyun 님 제보)
>>> [(x, y] for x in range(5) if x % 2 == 0 for y in range(5) if y % 2 == 1]
=>
>>> [(x, y) for x in range(5) if x % 2 == 0 for y in range(5) if y % 2 == 1]
상편 752쪽 첫 번째 코드 네 번째 줄 (Jae* Hyun 님 제보)
[1, 0 1]
=>
[1, 0, 1]
상편 755쪽 첫 번째 코드 첫 번째 줄 (Jae* Hyun 님 제보)
>>> def timefour(S):
=>
>>> def timesfour(S):
상편 758쪽 두 번쨰 코드 마지막 줄 (Jae* Hyun 님 제보)
'0 : 1 : 2 : 3 : 4 : 0 : 1 : 4 : 9 : 16"
=>
'0 : 1 : 2 : 3 : 4 : 0 : 1 : 4 : 9 : 16'
상편 770쪽 코드 밑에서 두 번째 줄 (Jae* Hyun 님 제보)
>>> len(p1) p1[0], p1[1]
=>
>>> len(p1), p1[0], p1[1]
(* 쉼표 누락 추가)
하편 1116쪽 표 제목
표 30-3 => 표 30-1